 How to resolve AdBlock issue?
How to resolve AdBlock issue? Auphonic Leveler
auphonic aus Österreich bietet auf seiner Web-Seite ein Dienst für die Normalisierung, bzw. Lautheitsoptimierung an. Neben diesem Service werden aber auch Software-Lösungen angeboten. Eine der angebotenen Lösungen ist der in diesem Test vorgestellte Auphonic Leveler.
Konzept
Die Lautheitsoptimierung spielt eine immer größere Rolle. Mittlerweile gibt es ja auch viele Werkzeuge um Lautheit zu analysieren und dann entsprechend den Pegel, bzw. Pegelverlauf, einzustellen. Der Auphonic Leveler vereint Analyse- und Bearbeitungswerkzeug in einem und gestattet die Batch-Bearbeitung von Dateien, also die weitgehend automatisierte Bearbeitung von Audiodateien.
Die Software steht sowohl für Mac OS X ab Version 10.6 (64 Bit) als auch für Windows-Betriebssystem ab Windows 7 (32 oder 64 Bit) zur Verfügung. Es handelt sich dabei um eine Stand-Alone-Software - also keine Einbindung in andere Software-Lösungen sondern eine völlig selbstständige Lösung. Neben der Beeinflussung des Pegels - und somit der Lautheit - bietet das Programm auch noch weitere Bearbeitungsmöglichkeiten. Wir schauen und daher einmal die Bedienoberfläche etwas genauer an.
Bedienung
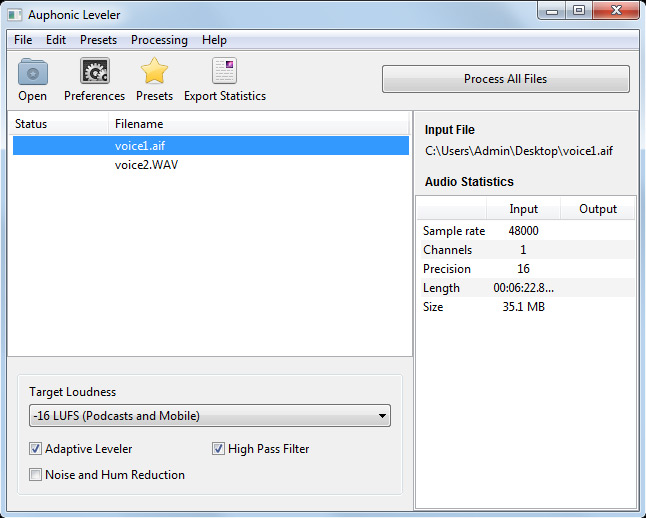
Nach dem Öffnen des Programms geht zunächst ein Fenster auf. In der Programmleiste befinden sich vier Icons zum Laden der Dateien die bearbeitet werden sollen, zum Aufrufen der Einstellungen (dazu später mehr) zum Speichern und Laden von Presets/Einstellungen sowie zum Exportieren von Bearbeitungsstatistiken. In der rechten Hälfte werden Daten zum selektierten File ausgegeben und im Kopf gibt es, wenn die Bearbeitung gestartet ist, ein Balken für die Visualisierung des Bearbeitungsfortschritts.
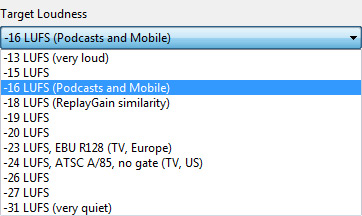
Aber als erstes muss man einige Einstellungen machen. Die wichtigste ist natürlich die Ziellautheit die man vorgibt. Diese ist direkt unter der Liste auswählbar. Hier sind typische und sinnvolle Werte anwählbar, wie -23 dB LUFS für die EBU Empfehlung R128, -16 dB ULFS zum Beispiel für Anwendungen wie YouTube-Videos oder -13 dB LUFS für reine Musikanwendungen hoher Lautheit (s. Abb. unten).
Es gibt drei grundsätzliche Bearbeitungsfunktionen die man individuell für ein Bearbeitungsdurchgang anwählen kann und zwar eben die adaptive Pegelanpassung für die dynamische Lautheitsoptimierung, ein zuschaltbares Hochpassfilter - sinnvoll für das Entfernen von tieffrequenten Störgeräuschen - sowie dann noch eine Rausch- und Brummunterdrückung.
Alle weitergehenden Einstellungen erfolgen über das Anwählen des Preferences Icons. Es geht dann ein neuer Dialog mit sechs Reitern auf, wo Detaileinstellungen vorgenommen werden können (s. Abb. unten).
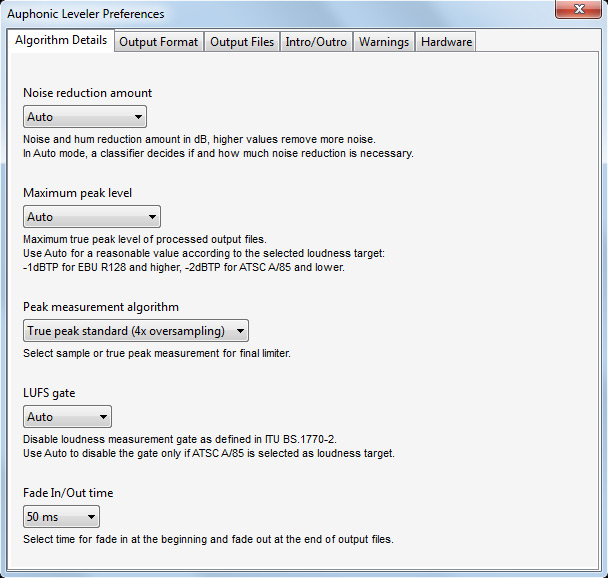
In den "Algorithmus Details" lässt sich z. B. die Stärke der Rauschunterdrücken wählen und zwar in: automatisch, 3, 6, 9, 12, 15, 18, 24, 30 und 100 dB (was im Prinzip einer vollständigen Entfernung entspricht). Weiter lässt sich neben der Lautheit auch der maximale Audiospitzenpegel wählen und zwar: Maximum Peak Level: automatisch, 0, -0,5, -1,0 (EBU R128), -1,5, -2 (ATSC A/85), -3, -4, -5, -6, -9 dBTP. Zudem gibt es zwei Verfahren für die Detektion der Spitzen (Peak measurement algorithm) und zwar True Peak mit vierfach Oversampling oder Sample Peak Level. In der ITU BS.1770-2 ist ein Gate vorgesehen. Wenn dieser Schwellwert unterschritten wird, erfolgt ggf. keine Anpassung, bzw. besser gesagt der Wert wird nicht für die Lautheitsanpassung berücksichtigt. Man kann hier in der Software die Gate-Funktion auf automatisch, fest auf -10 LU oder auf keine Gate-Funktion stellen. Weiter lässt sich eine Fade In/Out-Time am Dateianfang und Ende festlegen. Die einstellbaren Werte hierfür sind: 50, 100, 150, 200 oder 500 Millisekunden.
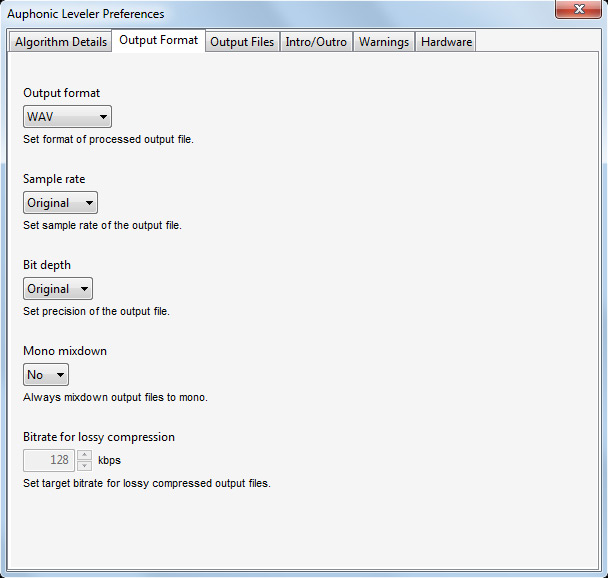
In dem zweiten Reiter befindet sich der Dialog für das Ausgabeformate. Hier lässt sich einmal das Dateiformat einstellen und zwar WAV, WAF Floating Point, AIFF, MP3, FLAC, Ogg Vorbis sowie die Abtastrate und zwar auf die Quellabtastrate oder fest auf 44,1 oder 48 kHz mit Abtastratenwandlung und auch die Wortbreite lässt sich fest auf 16, 24 oder 32 Bit einstellen oder auch auf die Wortbreite der Quelle - also unverändert.
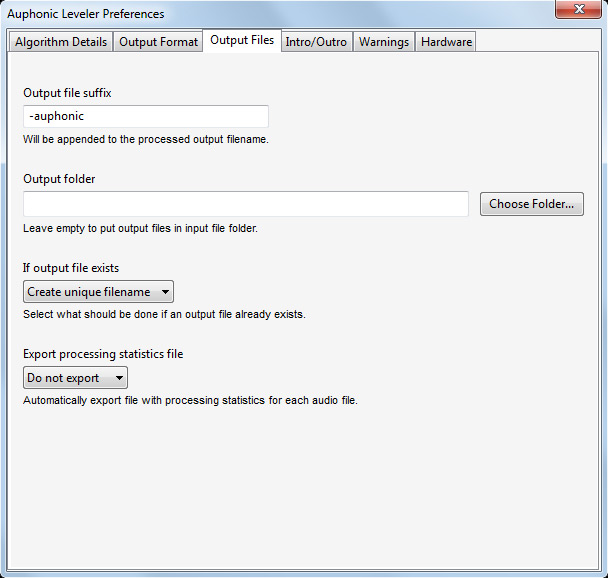
Dann gibt es noch über den Reiter "Output FiIes" einen Dialog für Dateien bez. Namensgebung und Zielordner etc. Es lässt sich z. B. in dem Dateiname eine Namensergänzung (Suffix) hinzufügen, damit man die bearbeiteten Dateien direkt erkennen kann, der Zielordner für die bearbeiteten Dateien lässt sich festlegen und es kann auch definiert werden, was passieren soll, wenn der Ausgangsdateiname schon existiert, also ob ein anderer Dateienamen verwenden werden soll, ob die Datei überschrieben oder erst gar nicht exportieren werden soll. Dann lässt sich auch noch das Format der zu exportierenden Statistikdatei definieren (JSON-, Text-, oder YAML-Datei).
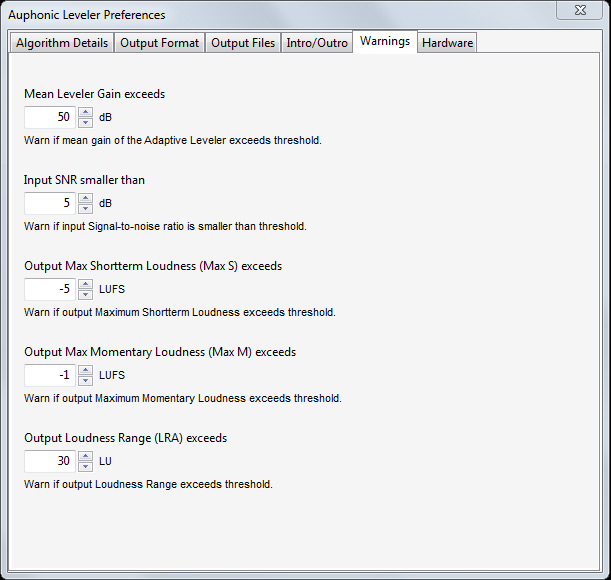
Weiter lassen sich über den Reiter "Warnings" verschiedene Schwellwerte einstellen und zwar für maximale Verstärkung des adaptiven Gain Levelers, minimaler Signal/Störabstand, maximale Kurzzeit-Lautheit, maximale aktuelle Lautheit und Maximalbereich der Ausgangslautheit.
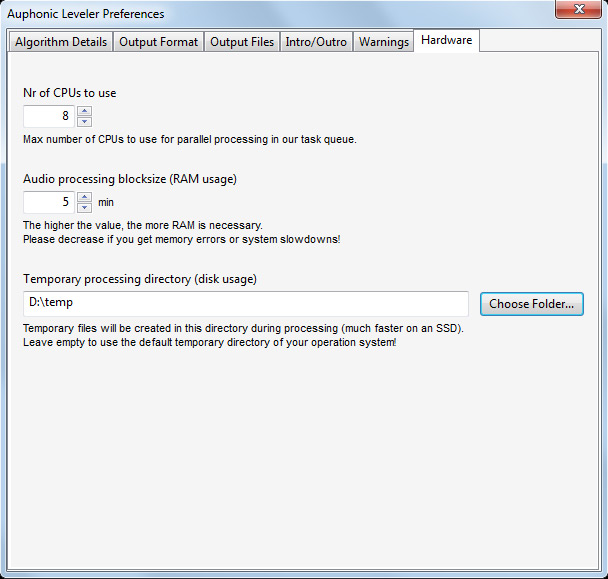
Auch auf die Rechner-Hardware kann man Einfluss nehmen, in dem man im Hardware-Dialog die Prozessoranzahl begrenzt und die Audiobearbeitungsblockgröße verändert, die Einfluss auf den benötigten RAM-Speicher hat. Das temporäre Verzeichnis für den Bearbeitungsvorgang lässt sich hier auch individuell eingeben.
Interview
Wir haben mit Georg Holzmann von auphonics auch noch ein Interview geführt, das auch noch weitere Einblicke in die Software und das Konzept gibt. Georg Holzmann ist ein Audio-Enthusiast mit Interesse an Maschinellem Lernen, Signalverarbeitung, Computermusik und Elektronische Musik, Open Source Software, Webentwicklung und vieles mehr. Diskussionen und Fragen von Podcastern weckten bei ihm die Idee zu Auphonic, wo er für Audioalgorithmen, Maschinelles Lernen und Software-Entwicklung zuständig ist. Er studierte Toningenieur an der TU/Kunstuniversität Graz und Informatik mit Fokus auf Maschinelles Lernen an der TU Berlin.

Das Team - von links nach rechts: André Rattinger, Ferdinand Fuhrmann, Christoph Pojer, Georg Holzmann, Florian Hollerweger
proaudio.de: Wie hat den alles bei auphonic angefangen und wer steckt hinter auphonic?
Georg Holzmann (auphonic): Entstanden ist Auphonic in der Podcasting Szene: dort ist ein Problem, dass die meisten Podcaster nicht viel Erfahrung mit Audiobearbeitung haben und Kompressoren, Limiter, usw. für Laien meist unmöglich einzustellen sind - alles ist viel zu kompliziert, Darum haben wir 2011 angefangen an Algorithmen zu arbeiten, welche diesen Prozess automatisieren können. Bei uns werden Audiodaten zuerst klassifiziert und danach dementsprechend bearbeitet - so wie das ein Toningenieur auch manuell macht. Wir versuchen dabei hauptsächlich technische Prozesse zu automatisieren, keine künstlerischen.
proaudio.de: Ihr bietet ja auch ein Online-Processing an. Was hat Euch bewogen auch dedizierte Applikationen für den lokalen DAW-Betrieb anzubieten? An wen wenden sich eigentlich Eure verschiedenen Modelle Online und DAW-Software?
Georg Holzmann (auphonic): Unser Online Tool wurde im März 2012 veröffentlicht und war unser erstes Produkt. Es ist immer noch das meist genutzte, da es auch neben den Audioalgorithmen noch eine Vielzahl von anderen Features beinhaltet wie automatisches Encoding in verschiedene Dateiformate inklusive aller Metadaten, Videobearbeitung, automatische Distribution auf externe Server wie FTP, YouTube, SoundCloud, Google Drive, Dropbox und vieles mehr.,
Einige unserer User wollten jedoch eine lokale Version unserer Algorithmen, einfach um den Upload zu sparen bzw. auch aus Datenschutz Gründen. Deswegen haben wir Anfang 2014 die Desktop Version des Auphonic Levelers veröffentlicht. In den letzten Jahren hat sich das Bewusstsein bezüglich Lautheit (EBU R128, etc.) auch enorm gesteigert, was ein zusätzlicher Nutzen unserer Software ist. Wir bieten Lautheitsnormalisierungen und viele andere Algorithmen vollkommen automatisiert an und sind meist auch noch billiger als ähnliche Tools, die sich ausschließlich auf Lautheitsnormalisierung konzentrieren.
proaudio.de: Wie geht der Leveler mit Störgeräuschen um, bzw. wie detektiert er diese?
Georg Holzmann (auphonic): Wir erkennen, wo in einer Datei verschiedene (konstante) Hintergrundgeräusche sind, z. B. zuerst eine Außenaufnahmen, dann eine Innenaufnahme. Danach wird bei jedem Hintergrundgeräusch ein Rauschprofil erstellt, dieses wird dann vom Gesamtsignal entfernt um das Rauschen zu mindern. Unsere Algorithmen entscheiden auch automatisch, wieviel Rauschentfernung gemacht werden soll, so dass keine Artefakte entstehen. Ähnlich funktioniert es z.B. auch bei der Brummentfernung, hier wird wiederum zuerst klassifiziert, ob und welcher Netzbrumm vorhanden ist, also 50 Hz oder 60 Hz Grundfrequenz und danach werden die einzelnen Teiltöne identifiziert und entfernt.
Praxis
Vorweg noch der Hinweis, dass es auf der Web-Seite von auphonics eine zwei Tage Probelizenz gibt, um so das Programm im praktischen Betrieb testen zu können. Vieles was die Bedienung angeht findet man auf der Hersteller-Web-Site. Es lohnt sich da mal ein Blick drauf zu werfen.
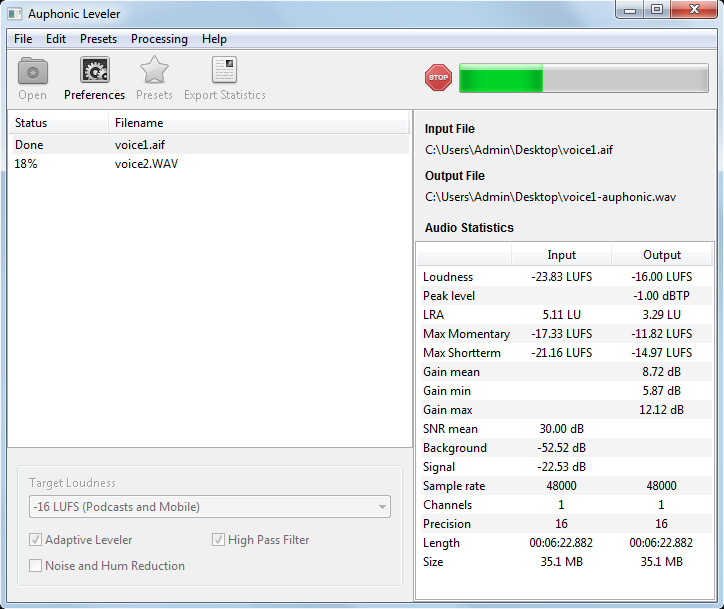
Wir haben die Applikation in der Version 1.4 auf einem Steller-Online SO-APC3 (2011) unter Windows 7 getestet. Wir haben dabei sowohl Audiodateien mit Dialogen als auch Musik bearbeitet.
Bei den Dialogen haben wir u. a. ein File mit zwei Sprechern in einer Interview-Situation und einem stark hörbaren 50-Hz-Brummen und leichtem Rauschen processed und zwar sowohl die Störsignale entfernt als auch den adaptiven Leveler für eine Lautheitsoptimierung und das auch mit dem zugeschalteten Hochpaß eingesetzt. Die Ergebnisse waren für eine automatisierte Bearbeitung sehr überzeugend. Sehr schön war das die eigene Dynamik des Material weitgehend erhalten blieb. Die Anpassung zwischen den sehr unterschiedlich ausgepegelten Sprechern gelang ebenfalls sehr gut. Die Artefakte durch das Entrauschen und Entbrummen waren selbst bei Maximaleinstellung noch so, dass man das Material problemlos ohne weitere Bearbeitung nutzen konnte, dabei wurden die Störkomponenten bei der Einstellung 100 dB wirklich restlos beseitigt. Um das durch manuelle Bearbeitung in der gleichen Qualität zu erreichen hätte man einiges an zeitlichen Aufwand treiben müssen. Die Regelvorgänge des adaptiven Leveler Algorithmus sind sehr smooth und angenehm. Man merkt bei Bearbeitung von sehr unterschiedlichem Audioeingangsmaterial relativ schnell, dass hier viel aus praktischen Erkentnissen in den Algorithmus des Auphonic Levelers eingeflossen sind.
Sprache ist eine Sache und Musik eine ganz andere. Aber auch hier schlägt die der Auphonic Leveler sehr gut. Dabei wurde sowohl klanglich sensibles Material bearbeitet wie Orchesteraufnahmen, als auch Attack-lastiger Pop oder sehr verdichtetes Material. Mit allem kam der Auphonic Leveler sehr gut klar - natürlich kein Ersatz für manuelles Mastering aber für einen automatisierten Prozess exzellent.
Was die Bearbeitung angeht so sind die Zeiten je nach Einstellung und Quellfiles unterschiedlich aber um mal so eine Idee zu bekommen hier Zeiten von zwei Audiodateien die wir bearbeitet haben. Eine Pop-Musik-Datei mit 16 Bit, 44,1 kHz Abtastrate und 24 Minuten Länge dauert für reines adaptives Leveling ca. 35 Sekunden. Mono-Sprachdateien mit 48 kHz von sechs Minuten Länge mit allen drei Bearbeitungsfunktionen (Leveling, Hochpaß und Entrauschen/Entbrummen) und vierfach Oversampling Peak-Messung dauerten zum Teil genauso lange. Ein 3 Minuten und 30 Sekunden langes Musikstück, 16 Bit, 44,1 kHz Stereo dauerte für das reine Leveling gerade mal 13 Sekunden. Soweit hier einige Beispiele. Aber diese Zeiten sind absolut akzeptabel.
Wir haben mit verschiedenen Meßgeräten auch einmal die erzielten Lautheitswerte analysiert. Eine Überschreitung von Lautheitswerten konnten wir dabei nicht feststellen sondern viel mehr blieb man ein Bruchteil eines dBs unter dem eingestellten Wert. Also auch hier alles absolut im grünen Bereich.
Kleiner Wehrmutstropfen war, dass zunächst bei einigen Dateien die wir bearbeitet haben, manchmal der Bearbeitungsprozess einfrohr. Der Grund lag in der Einstellung der Prozessoranzahl in dem Dialog Hardware. Der steht standardmäßig auf 8. Als wir den Wert auf 4 Prozessoren für unser Quad-PS-System umgestellt haben liefen alle Files ohne durch. Sonstiges Probleme oder Komplettabstürze konnten wir nicht feststellen oder produzieren.
Das einzige was man noch anmerken kann ist, dass vieleicht noch ein paar vorgefertigte Presets vom Hersteller für die Anwendergruppen hilfreich wäre, die sich nicht mit den Detailparametern beschäftigen möchten denn das Auphonic Leveler ist ja ein Werkzeug sowohl für Profis als auch gerade für Nicht-Audio-Profis, z. B. aus dem Videobereich.
Fazit
Die kommerzielle Auphonic Leveler Lizenz für Firmen und Universitäten kostet 299 Euro. Für den nichtkommerziellen Individualgebrauch gibt es noch ein Lizenzangebot für 69 Euro. Der Preis ist für die Leistung auf jeden Fall gerechtfertigt und wieder schnell armortisiert.
Ich sehe einen sehr großen Anwendungszweig im Bereich Broadcast für die Vorbereitung von Interviews und Reportagen und vor allem im Bereich der A/V-Post-Production etc. Beides Bereiche, in denen man schnell zum Ziel kommen muss und dies mit möglichst wenig Aufwand und möglichst gutem Ergebnis und genau das leistet der Auphonic Leveler. Wirklich ein super Werkzeug speziell für diejenigen, die keine Zeit haben manuell das Optimale aus dem vorliegendem Material herauszuholen.